数据竞争
大多并发 bug 最后都会体现为数据竞争 (Data Race)
对于顺序程序而言,函数 f() 返回之后就已经完成了所有的状态修改,对于其他部分而言这个修改是立即生效的;如果对于并发程序而言模式的切换也在瞬间完成,那就不会导致并发的问题
然而实际上模式的切换需要时间,执行的操作在未来一段时间之后才会就绪,但是我们在实际编程时总是容易有“立即生效”的肌肉记忆,这就导致了并发问题的可能性
不过对于函数式编程而言,操作不存在对外状态的修改,没有副作用(只会操作局部变量),这就不会导致并发问题
Data Race 发生的实质是不同的线程同时访问同一内存,并且至少有一个是写,形象的理解就是不同的内存访问在“赛跑”,跑赢的操作先执行
Not that easy: 虽然我们将数据竞争形象地比喻为“赛跑”,但实际上,哪一个操作能“跑赢”并没有想象中那么简单和确定,其复杂性主要体现在以下几个方面
弱内存模型 (Weak memory model):在现代处理器架构中,为了提升性能,处理器可能会对内存操作进行重排序。这意味着,不同的线程或“观察者”在不同时间点看到共享内存的状态可能是不一致的。一个线程对内存的写入操作,可能不会立即对所有其他线程可见,导致不同线程观察到不同的结果。这种内存模型的一致性问题使得确定哪个操作“先发生”变得非常困难且不确定。
未定义行为 (Undefined Behavior):从 C++11 标准开始,数据竞争被明确规定为未定义行为。这意味着,如果你的程序发生了数据竞争,编译器可以自由地产生任何行为,无论是崩溃、产生错误结果,还是看似正常运行但结果不可预测。这使得数据竞争成为非常危险且难以调试的并发错误,因为它的表现可能是不确定、不稳定的。
多线程与多内存的复杂交互:在实际的并发程序中,通常会有多个线程同时访问多个共享内存位置。这些线程和内存之间存在复杂的读(R)写(W)交互。一个线程对一个内存位置的写入可能影响到其他多个线程对该位置的读取,同时,多个内存位置之间也可能存在复杂的依赖关系和缓存一致性问题。这种错综复杂的交互网络进一步加剧了数据竞争的不可预测性。
为了消灭数据竞争,我们需要保证程序的 serializability ,可能竞争的内存访问要么互斥,要么同步
实际编程中遇到的数据竞争 bug 大多属于上错了锁和忘记上锁两种情况的变种
Case 1: 上错了锁
| |
Case 2: 忘记上锁
| |
但是实际系统面临的情况比这复杂的多,因为
- 内存可以是地址空间的任何内存,比如全局变量、堆内存分配的变量、程序的栈……
- 访问可以发生在任何代码,比如自己的代码、框架代码、一行没读到的汇编指令、某条 ret 指令
- “一行没读到的汇编指令”造成的访问的情况有编译器优化造成的指令重排、硬件层面弱内存模型的内存访问重排、还有一些高层语言操作的隐式内存访问
- 实际系统中虽然难以避免,但是会尽可能保证底层的结构对上层尽可能封闭来防止这种错误
死锁
死锁 (Deadlock) 是指一个群体中的每个成员都在等待其他成员(包括自身)采取行动的状态
死锁有两种:
AA-Deadlock: 自己等待自己
| |
这样的错误虽然看起来很傻,但是在真实程序复杂的控制流中是可能出现的
ABBA-Deadlock: 两个(多个)锁互相等待
比如 16. 并发控制:同步信号量 中的哲学家吃饭问题
How?
想要消除死锁,可以从死锁产生的必要条件入手,通常称为霍尔德(Holt)条件, 可以形象地把锁看成袋子里的球:
- 互斥 (Mutual-exclusion):
- 一个口袋一个球,即资源是互斥的,一次只能被一个线程占用
- 如果资源可以共享(例如,只读文件),则不会发生死锁
- 请求并保持 (Wait-for):
- 得到球的人想要更多的球,即一个线程在持有至少一个资源的同时,又在等待获取其他被占用的资源
- 如果线程在请求新资源时,必须释放所有已持有的资源,则可以避免死锁
- 不可抢占 (No-preemption):
- 不能抢别人的持有的球,即资源不能被强制从持有者手中抢走,只能由持有者自愿释放
- 如果系统可以抢占资源(例如,通过中断强制释放),则可以打破此条件
- 循环等待 (Circular-chain):
- 形成循环等待的关系,即存在一个线程链 $ T_1, T_2, \ldots, T_n $,其中 $ T_1 $ 正在等待 $ T_2 $ 占用的资源,$ T_2 $ 正在等待 $ T_3 $ 占用的资源,依此类推,$ T_n $ 正在等待 $ T_1 $ 占用的资源
这四个条件是死锁发生的必要条件,这意味着只要打破任何一个条件,就不会发生死锁了,理论上,我们可以通过破坏这些条件来预防或避免死锁。
然而,将这套理论应用于实际复杂系统时,会发现它是一个正确的废话,不能称为一个合理的 argument
- 对于玩具系统/模型:可以直接证明系统是 deadlock-free 的,因为其状态空间有限,可以通过穷举或形式化方法进行验证
- 对于真正的复杂系统:很难判断哪个条件最容易被打破,或者说,在保证系统功能性和性能的前提下,打破某个条件可能带来巨大的复杂性或性能开销
实际编程中通常会采用其他策略来预防死锁:
一个常见的方法是锁排序,其核心思想是:
- 任意时刻系统中的锁都是有限的。
- 给所有锁编号(或者定义一个全局的获取顺序)
- 线程在获取多个锁时,严格按照从小数到大的顺序获取锁
- 这种策略也相对容易检查和验证。
这样在任意时刻总有一个线程获得“编号最大”的锁,于是这个线程总是可以继续运行
然而这种方法在实践中会遇到问题,代码的文档并不总是可靠,并且对于复杂系统这是难以扩展的;而最好的锁是封装的,并不会暴露出来,这样使用代码的人甚至不需要知道正在使用锁
Some Methods
为了应对死锁,尤其是 ABBA-Deadlock,一些工具被开发出来,例如 Linux 内核中的 LockDep
一个简单的想法:
- 每次
acquire/release锁时,都打印一个日志 - 如果任何线程存在 $ A\to B $ 和 $ B\to A $ 的依赖关系,就报告死锁
- 这可能导致 false positives ,比如存在同步机制 ($ A\to B\to \mathrm{spawn}\to B\to A $)
通过优化这个方法可以得到一个相对高效的实现:动态维护“锁依赖图“并检测环路
原子性和顺序违反
并发编程是本质困难的,我们只能用 sequential 的方式来理解并发:把程序分成若干的块,每一块的操作都是原子的,无法被打断
并发的机制可以分成两类:
- 互斥锁实现原子性
- 忘记上锁会导致原子性违反 (Atomicity Violation, AV)
- 条件变量/信号量实现先后顺序同步
- 忘记同步会导致顺序违反 (Order Violation, OV)
并发的机制完全是“后果自负”的,这也导致了 Threads cannot be implemented as a library ,因为?
有研究统计了很多真是系统存在的并发 bug,发现 97% 的非死锁并发 bug 都是原子性或顺序错误
Atomic Violation
代码被别的线程“强行插入”,即使分别上锁消除了数据竞争,还是会导致 AV
比如图中的例子: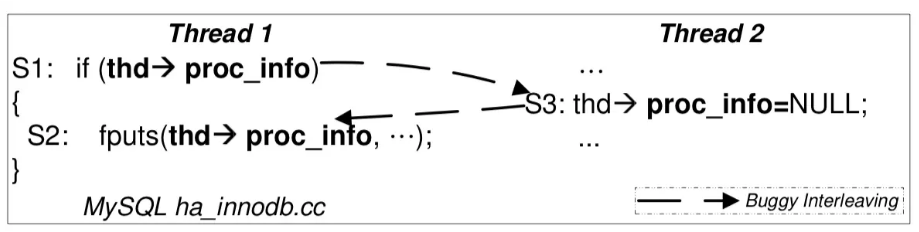
如果在 Thread 1 结束判断进入 if 之后 Thread 2 再执行,就导致了错误
并且注意到操作系统的状态也是共享状态,利用一样的原理还可能产生更难发现的 bug
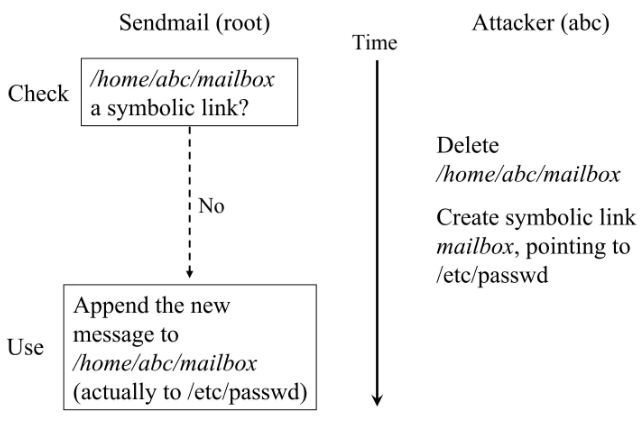
攻击者在 check 之后马上替换文件为符号链接,就可以造成权限问题等严重安全漏洞
Order Violation
事件没有按照预定的顺序发生,就会导致 OV ,比如
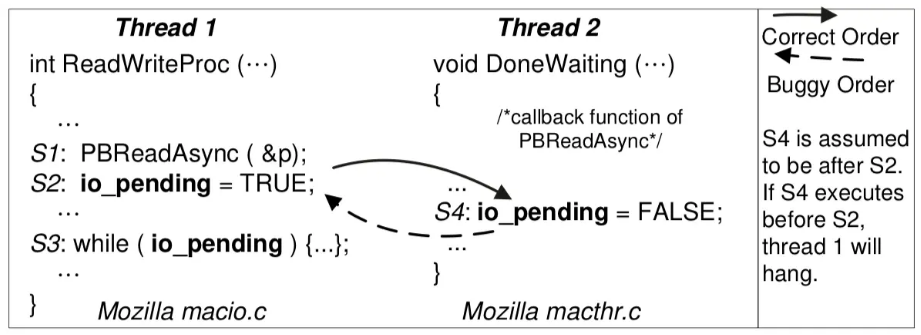
如果 Thread 2 中的 S4 发生在了条件变量的初始化之前,那么相当于全局的广播被吞掉了,就可能会导致 Thread 1 可能无法被唤醒
However
我们可以使用加强版的 LockDep 来解决这些问题,比如直接分析程序的日志,检查有没有不相交的锁,事件的 happens-before 关系是否正确……甚至也可以直接用启发式(或者 LLM )来分析日志是否正确
然而即使这样也不能解决真实世界的所有并发问题,比如这个 GhostRace 的例子
- 实现了正确的互斥、正确的同步 $ \text{use}\to\text{free} $
| |
实际上导致问题的是现代 CPU 的推测执行的特性,为了提高效率会提前通过分治预测器预判执行的方向,提前执行指令
这段代码中线程 $ T_{B} $ 的 CPU 会在正式获得锁并判断 NULL 之前就提前推测性执行 if 块内部的代码,如果此时 $ T_{A} $ 恰好释放了 obj-something 指向的内存,那么 $ T_{B} $ 中就会访问到一块已经被释放的内存,从而通过缓存等方式泄露信息(虽然错误执行的语句已经回滚了,但是被加载到缓存中的数据等不会回滚),通过这种方式就有可能访问到程序本来没有权限访问的内存,从而产生安全漏洞
这种并发 bug 的根源在于软件层面的同步无法约束硬件层面的行为