科普性质,简单记录一下
1-Bit 的存储:磁铁
要实现“持久化”存储,核心是要找到一个能反复改写的状态,很容易想到能够利用磁的特性,这就有了磁带的初步想法:
- 一个长条的带子上面均匀有磁性物质
- 定位到特定位置之后通过放大感应电流读取
- 用电磁铁改变磁化方向来写入数据
为了提高存储密度,可以把这样的带子给卷起来,于是就得到了磁带
这样的存储方式主要缺点是几乎不能随机读写(比如磁带收音机需要倒带),一般用于冷数据的存档和备份
为了解决这个缺点,可以想到用旋转的二维平面来替代卷起来的带子,这样读写延迟就不会超过旋转的周期,这就得到了磁鼓:

再在磁鼓的基础上进一步内卷,把用圆盘代替柱面,从而可以堆叠起来,进一步提高了存储密度,这就得到了磁盘:
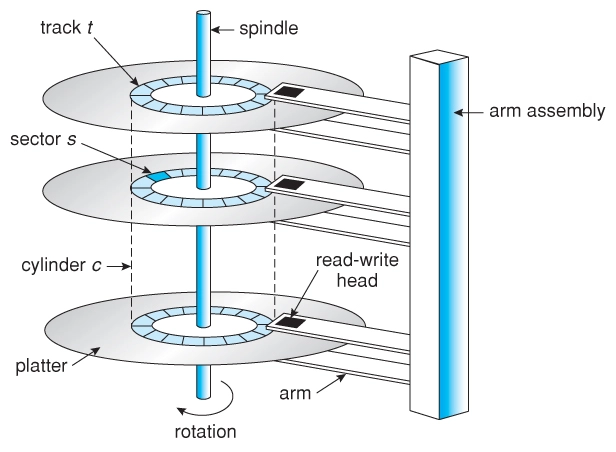
磁盘作为存储设备的随机读写性能虽然相比磁带有了很大的改善,但是还是需要等待定位到正确的位置,性能仍然不够优秀,为了读写定位到一个扇区通常需要花费几个毫秒的时间,这一点可以通过缓存和调度算法来缓解,让数据尽可能连续存储
当我们在磁盘的基础上把读写头和盘片本体分开,我们就实现了数据的移动,这也就得到了软盘,这是上个数据数据发行的主要方式,虽然性能和可靠性都比较低,但是胜在了便捷、可移动
1-Bit 的存储:挖坑
古人实现持久化存储的方式是在石头上刻字,也就是通过挖坑来存储信息,这种方式可以跨越非常长的时间
而现代工业使我们可以挖出更加精细的坑,从而可以存储更高密度的信息
为了读取这样的信息,我们可以从光学的角度考虑:在反射平面上挖粗糙坑,激光扫过表面,在平面会反射回来,在坑里会发生漫反射,于是我们只要检测是否收到反射光就可以识别是坑还是表面,这也就是光盘
光盘最有趣的特性是容易复制,我们要制造光盘可以先仔细地制造一张反转的盘片,坑的位置对应其表面的突起,之后只需要直接用这个盘片压制加热的塑料再镀上反射膜就可以得到一张光盘,这种方式可以达到极高的写入速度
当然这种挖坑方式的一个重要特性就是不能修改已经写入的内容的,很难填上一个已经挖了的坑(当然通过特殊的制造材料和工艺也是可以做到的),这也就是说里面存储的数据是 append only 的,想要修改之前的内容可以采用可持久化二叉树的结构
光盘作为存储设备,价格低的同时容量和可靠性都比较高,同时顺序读性能一般,随机读性能低并且很难写入,一个重要的应用常见就是数字时代的内容分发
现代这种挖坑的存储方式还有一种应用方式是回归古人石碑的形式,把信息刻在很稳定的材料上来做到永久存储
1-Bit 的存储:电荷
前两种存储介质都存在比较大的缺陷:
- 磁:依赖机械部件,从而无法避免 ms 级别的延迟
- 坑(光):挖坑效率低,同时填坑很困难
而电荷则是一种非常理想的存储介质:电子的密度极高,并且电路的速度极快(还天然并行)
在电路中实现 1-bit 的持久存储,一个想法是我们可以挖一个坑,两种状态分别是:
- 在坑里填入电子
- 从坑里放跑电子
而这就得到了闪存 (Flash Memory) :
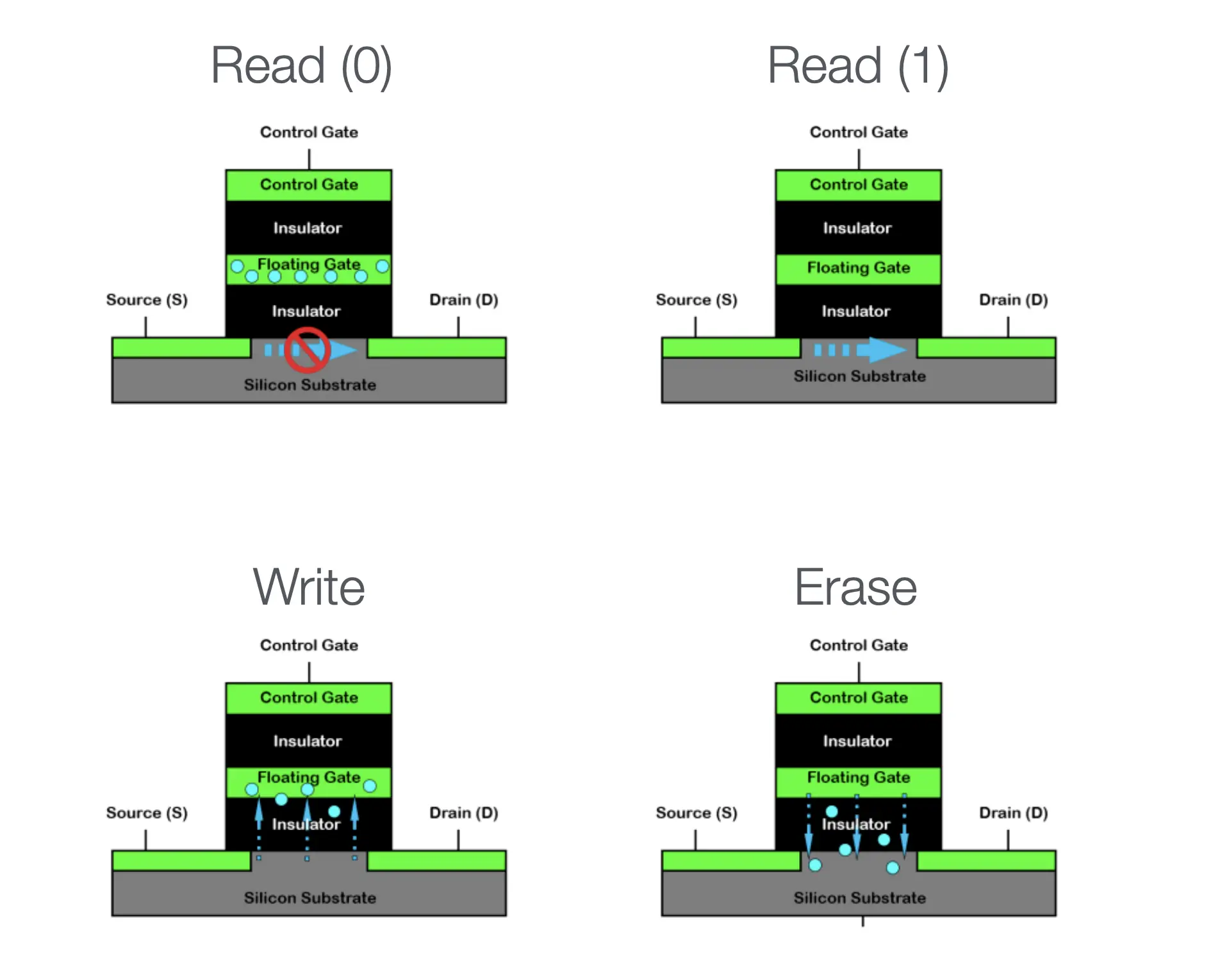 其作为存储设备,价格低,容量和可靠性高,而且读写性能极高(由于电路天然并行,所以容量越大,速度越快)
其作为存储设备,价格低,容量和可靠性高,而且读写性能极高(由于电路天然并行,所以容量越大,速度越快)
然而,闪存的物理原理也带来了其固有的缺陷,即会磨损 (wear out)
- 每次放电 (erase) 操作都无法 100% 将电子放干净,这会对存储单元造成微小的、不可逆的损伤
- 在经历数千或数万次擦写循环后,一些存储单元会因为累积的损伤而失效,无法再可靠地存储数据,这被称为 “死单元 (Dead Cell)”
为了解决闪存的磨损问题,并将其更好地呈现给操作系统,现代固态存储设备(如 SSD、U 盘、SD 卡)内部实际上都集成了一个微型计算机系统
这个系统运行着一层被称为 FTL (Flash Translation Layer) 的固件,它的核心功能之一是 磨损均衡 (Wear Leveling)
FTL 会记录每个物理块的擦写次数,当操作系统请求写入某个逻辑地址时,FTL 会避免总是写入同一个物理块,而是将写入请求重定向到一个较少被使用的物理块上,这种机制类似于操作系统中的虚拟内存,通过引入一个间接层(逻辑地址到物理地址的映射)来隐藏底层硬件的复杂性并优化其使用寿命
这也意味着,即便是便宜的 U 盘 或 SD 卡,其内部也可能包含一个 ARM 芯片来运行 FTL,而高性能的 SSD 则拥有更强大的处理器、缓存和更复杂的 FTL 算法,从而提供更长的寿命和更高的性能
这也解释了为什么我们不应该购买过于廉价的 U 盘,因为它们可能会在 FTL 上偷工减料,甚至伪造容量和厂商信息,导致数据丢失
存储设备与操作系统
块设备抽象
无论是旋转的磁盘还是闪存芯片,它们都不适合以单个字节为单位进行寻址,因为定位和元数据(如扇区头、ECC 校验码)的开销太大
因此,存储设备将它们的存储空间划分为固定大小的块 (Block),并以块为单位进行读写,这大大摊销了单次 I/O 操作的开销,这些设备在操作系统中被称为块设备 (Block Devices)
操作系统看到的是一个线性的、从 0 开始编号的块数组 struct block disk[NUM_BLOCKS],应用程序可以直接像读写文件一样读写块设备(例如 /dev/sda),但这样做的效率很低,如果随机读写一个字节,操作系统和设备硬件最终可能会读取或写入整个块,导致读/写放大 (read/write amplification) 的问题,因此,上层的文件系统被设计为能够感知“块”的存在,并以块为单位来组织和管理数据
为了高效地管理对块设备的访问,操作系统提供了一个专门的 I/O 栈
在 Linux 中,上层文件系统或应用程序通过块 I/O (Bio) 层提交请求,Bio 层提供了一个请求/响应接口,它将上层的读写请求封装成 struct bio 结构体,这些请求被放入队列中,等待 I/O 调度器 (I/O Scheduler) 进行处理,调度器会根据策略(例如合并相邻的请求、排序请求以减少磁头寻道时间)来优化队列
现代 Linux 内核使用多队列块 I/O (Multi-queue block I/O, blk-mq) 机制,为每个 CPU 核心 分配独立的请求队列,充分利用了现代多核处理器和高速 SSD 的并行性
最终,由设备驱动程序将处理好的请求发送给硬件执行