由于高性能计算场景下的并行编程任务的特性,OpenMP 可以通过简单受限的语法极大地化简了并行编程的复杂性,在普通的串行代码中添加一些指令就能够实现高效并行化。
1. What is OpenMP?
OpenMP (Open Multi-Processing) 是一种用于共享内存多处理器系统并行编程的 API。它通过在 C, C++, 或 Fortran 代码中添加 #pragma 的方式,让开发者可以轻松地将串行代码并行化,而无需手动管理复杂的线程创建、同步和销毁过程。
2. The OpenMP Programming Model
共享内存模型:所有线程在同一个地址空间中共享数据。这意味着不同线程可以访问相同的内存位置,并且可以共享变量的值。
共享变量:在并行区域中,默认情况下,大多数变量是共享的,即所有线程都可以访问和修改这些变量的值。
私有变量:某些情况下,我们可能希望每个线程拥有变量的私有副本,这样不同线程之间不会相互干扰。OpenMP 通过
private指令指定这些变量。数据竞争(Race Condition):由于多个线程同时访问和修改共享变量,可能会导致数据竞争问题。为了避免这种情况,OpenMP 提供了同步机制,如
critical和atomic等。
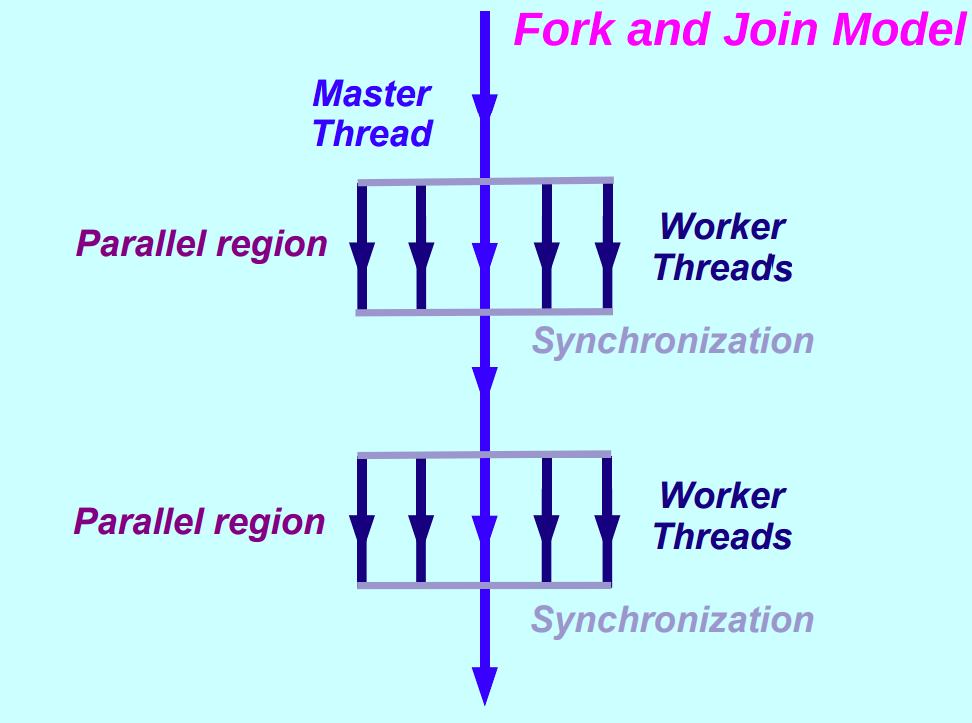
并行区域(Parallel Region):是 OpenMP 编程的核心概念。它是由编译器指令 #pragma omp parallel 指定的一段代码,告诉 OpenMP 在这段代码中创建多个线程并行执行。
Fork-Join 执行模型:从单线程开始执行,进入并行区域开始并行执行,在并行区域结尾进行同步和结束线程。
3. Core Directives and Constructs
OpenMP 的功能主要是通过编译指令(Directives)和相关的子句(Clauses)来实现的。
parallel:用于创建一个并行区域。
| |
for:用于并行化for循环,必须与parallel结合使用。它会自动将循环迭代分配给不同的线程,这是 OpenMP 最常用、最高效的指令之一。
| |
sections:用于将不同的、独立的任务代码块分配给不同线程。适用于任务并行而不是数据并行。
| |
4. Data Scoping
数据作用域定义了并行区域中变量如何被线程共享或者私有,OpenMP 通过子句 clauses 来控制变量属性。
shared(list):变量在所有线程间共享同一份内存,这是大多数变量的默认设置。读写共享变量通常需要同步。
| |
private(list):每个线程在并行区域中有自己独立的变量副本,线程之间相互独立,互不干扰。并行区域内申明的变量默认为私有的,并行区域外申明的变量需要显式申明 private。firstprivate(list):是private的一种特殊情况。私有副本会用主线程中原始变量的值进行 初始化。lastprivate(list):是private的另一种特殊情况。当并行结束后,循环中最后一次迭代(或sections中最后一个 section)的线程会将其私有副本的值拷贝回主线程的原始变量。
| |
reduction(operator:list):用于解决并行计算中的归约操作(如求和、求积)。每个线程会计算一个局部结果,并行区结束后,所有局部结果会通过指定的操作符 (+,*,-等) 合并到主线程的全局变量中,从而避免了竞争。- (规约的运算符规则)
| |
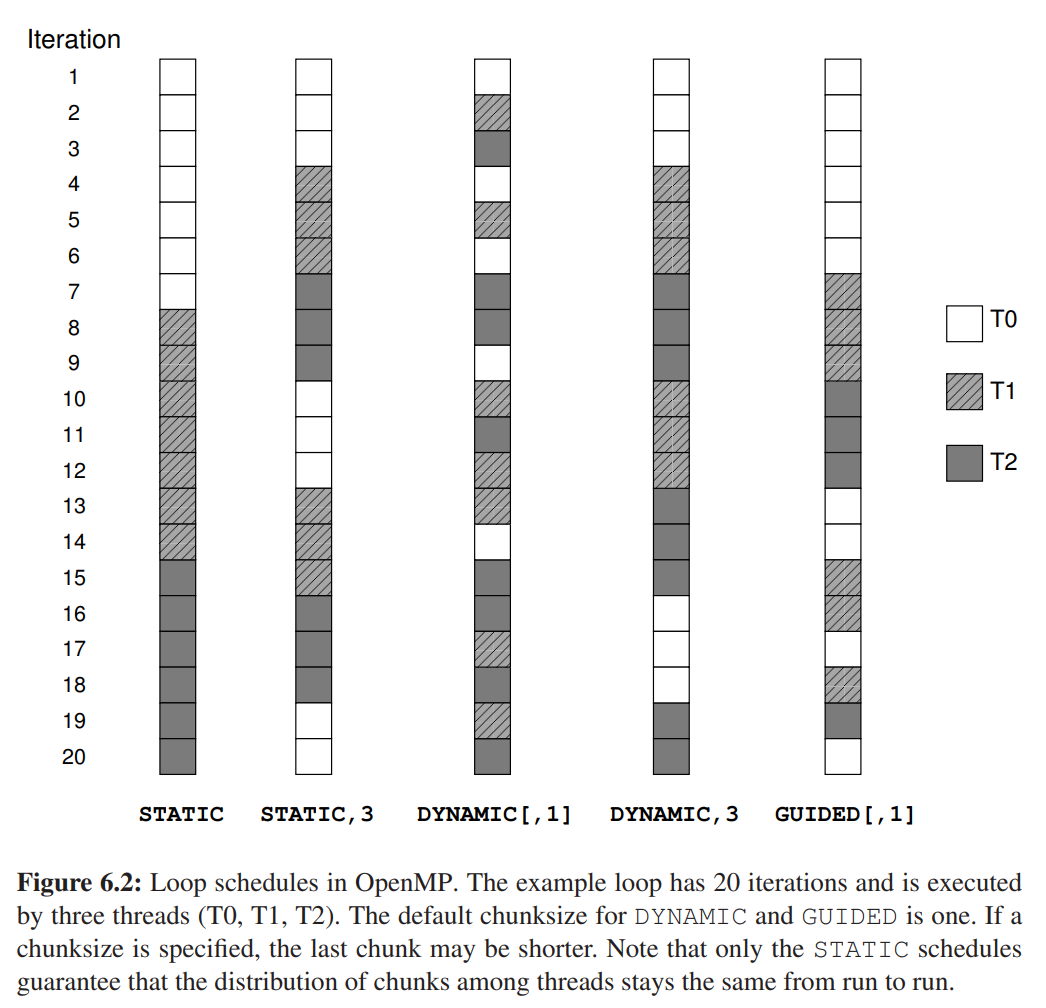
5. Loop Scheduling
当使用 omp for 时,OpenMP 需要决定如何将循环的迭代次数分配给线程。这通过 schedule 子句控制,其选择会影响负载均衡 (Load Balancing) 和开销 (Overhead)。
schedule(static, [chunk_size]):静态调度。在编译时就将迭代平均分配好。开销最小,适用于每次迭代计算量都相等的循环。
| |
schedule(dynamic, [chunk_size]):动态调度。线程每次完成一个(或 chunk_size 个)迭代后,动态地去任务队列领取新的任务。开销较大,但适用于每次迭代计算量不均匀的场景。schedule(guided, [chunk_size]):引导式调度。动态调度的一种优化。开始时分配大块任务,随着任务剩余量减少,分配的任务块也越来越小。是static和dynamic的一种折中。auto:自动调度将调度策略的选择权交给编译器或运行时库,由它们决定最佳的调度方式。schedule(runtime):由环境变量OMP_SCHEDULE决定使用哪种调度策略,增加了灵活性。
6. Synchronization Control
同步是用来协调线程间的执行顺序和保证对共享数据访问的正确性。
critical:定义一个临界区,同一时间只允许一个线程进入该代码块,开销较大。atomic:针对单条内存更新语句(如x++,x = x + 1)提供原子操作。比critical更轻量,是保护简单更新的首选。barrier:一个同步点。所有线程必须执行到barrier处才会继续向下执行,没有任何线程可以提前。在并行区域末尾会有一个隐式的barrier。master:指定一块代码只由主线程执行。single:指定一块代码只由线程组中第一个到达的线程执行。
7. Environment Variables
OpenMP 允许通过环境变量在运行时控制并行行为,而无需重新编译代码。
OMP_NUM_THREADS:设置并行区默认使用的线程数,这是最常用的环境变量。OMP_SCHEDULE:当代码中使用schedule(runtime)时,该变量用于设定循环调度策略和块大小,例如:"dynamic,4"。OMP_PROC_BIND:控制线程与处理器核心的亲和性(绑定关系),对性能优化非常重要。
8. How to Compile and Run
编译 C/C++ 代码时,需要添加一个特定的编译器标志来启用 OpenMP 支持。
GCC / G++:
| |